Centos7系统上K8S (v1.28)集群部署
基于centos7 部署kubernete v1.28 集群,一个master节点,三个node节点
前置步骤
1、关闭防火墙
systemctl disable firewalld
systemctl stop firewalld2、关闭selinux(临时/永久)
# 临时禁用selinux(本示例是临时关闭的)
setenforce 0
# 永久关闭selinux
# 修改/etc/sysconfig/selinux文件设置
sed -i 's/SELINUX=permissive/SELINUX=disabled/' /etc/sysconfig/selinux
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config3、禁用Swap(交换)分区
swapoff -a
sed -i 's/.*swap.*/#&/' /etc/fstab安装Docker
1、更新yum源
yum update -y2、设置存储库
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo3、安装Docker (Engine) 及其它依赖库。
sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Installed:
containerd.io.x86_64 0:1.6.31-3.1.el7 docker-buildx-plugin.x86_64 0:0.14.0-1.el7 docker-ce.x86_64 3:26.1.1-1.el7
docker-ce-cli.x86_64 1:26.1.1-1.el7 docker-compose-plugin.x86_64 0:2.27.0-1.el7
Dependency Installed:
audit-libs-python.x86_64 0:2.8.5-4.el7 checkpolicy.x86_64 0:2.5-8.el7 container-selinux.noarch 2:2.119.2-1.911c772.el7_8
docker-ce-rootless-extras.x86_64 0:26.1.1-1.el7 fuse-overlayfs.x86_64 0:0.7.2-6.el7_8 fuse3-libs.x86_64 0:3.6.1-4.el7
libcgroup.x86_64 0:0.41-21.el7 libsemanage-python.x86_64 0:2.5-14.el7 policycoreutils-python.x86_64 0:2.5-34.el7
python-IPy.noarch 0:0.75-6.el7 setools-libs.x86_64 0:3.3.8-4.el7 slirp4netns.x86_64 0:0.4.3-4.el7_8
Complete!4、启动Docker,设置开机自启动,查看Docker状态为active (running) 即为启动成功。
$ sudo systemctl start docker
$ sudo systemctl enable docker
$ sudo systemctl status docker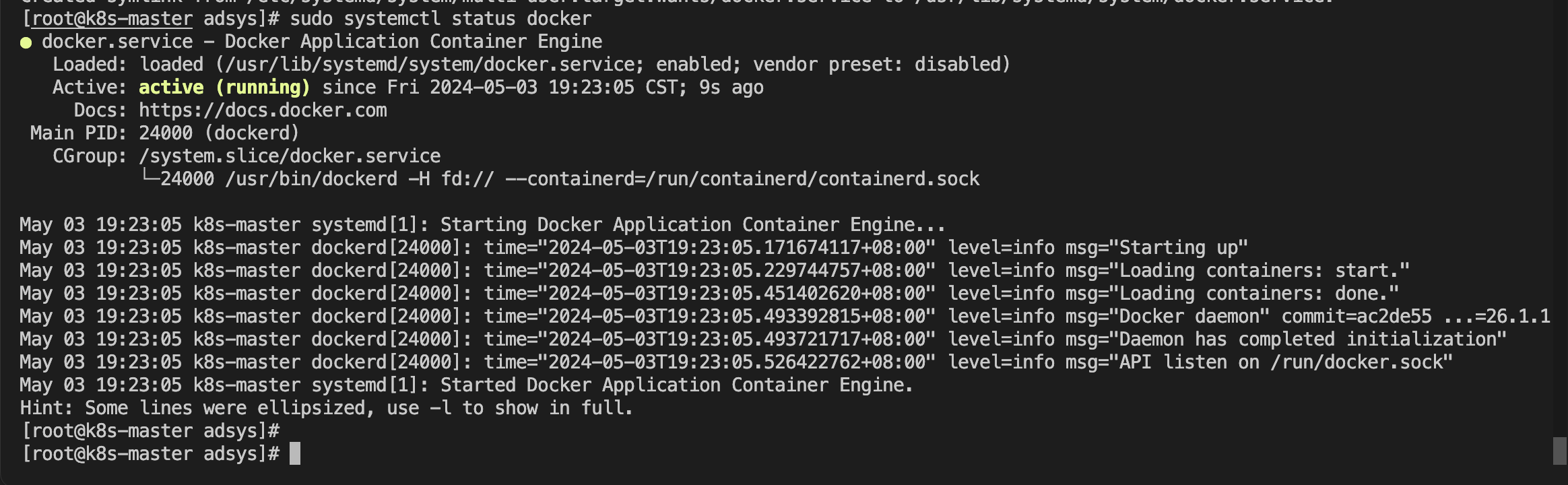
安装cri-dockerd
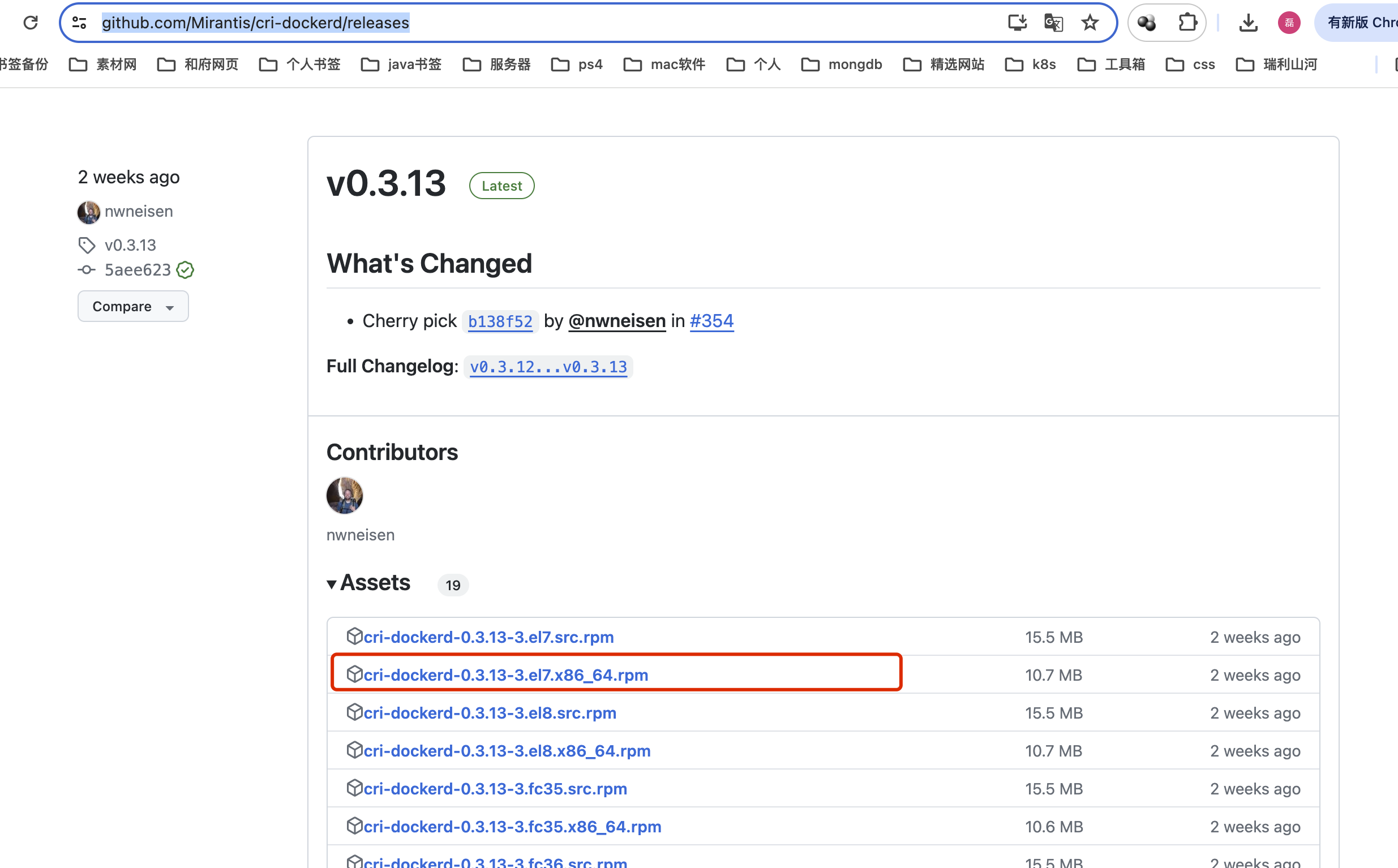
1、压缩包下载
建议本地下载完压缩包后再上传至服务器,压缩包文件地址: https://github.com/Mirantis/cri-dockerd/releases
2、解压
压缩包上传至服务器后,解压:
rpm -ivh cri-dockerd-0.3.13-3.el7.x86_64.rpm
3、重载系统守护进程→设置cri-dockerd自启动→启动cri-dockerd
$ sudo systemctl daemon-reload # 重载系统守护进程
$ sudo systemctl enable cri-docker.socket cri-docker # 设置cri-dockerd自启动
$ sudo systemctl start cri-docker.socket cri-docker # 启动cri-dockerd
$ sudo systemctl status cri-docker.socket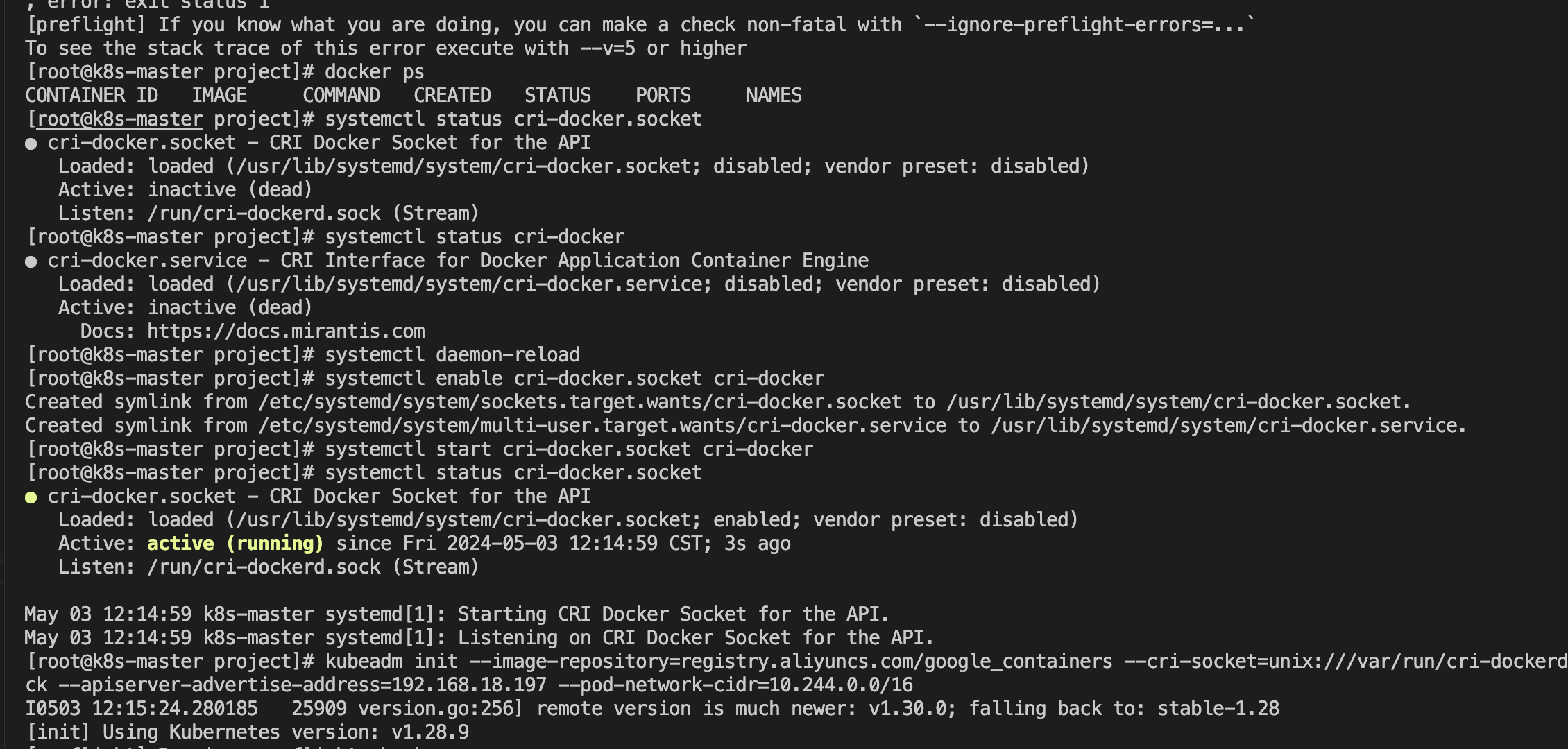
4、Docker和cri-dockerd设置国内镜像加速。
注意: ****** 需要改成自己阿里云的镜像加速地址
$ sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://*** */.mirror.aliyuncs.com"]
}
EOF
$ vi /usr/lib/systemd/system/cri-docker.service # 找到第10行ExecStart= 修改为
ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7
$ systemctl daemon-reload && systemctl restart docker cri-docker.socket cri-docker # 重启Docker组件,这个地方是个小技巧,连写会方便很多
$ systemctl status docker cir-docker.socket cri-docker # 检查Docker组件状态这一步如果跳过,会出现kubeadm init 健康检查超时,同时使用 journalctl -xeu kubelet | grep error 会出现如下错误,并且node无法加入master节点,会出现网络连接错误
error: code = Unknown desc = failed pulling image \\\"registry.k8s.io/pause:3.9\\\": Error response from daemon: Head \\\"https://us-west2-docker.pkg.dev/v2/k8s-artifacts-prod/images/pause/manifests/3.9\\\": dial tcp 64.233.187.82:443: i/o timeout\"" pod="kube-system/etcd-k8s-master" podUID="241c98dbd46abfef5832021e5d3ba767"安装Kubernetes
安装 kubeadm、kubelet 和 kubectl,配置yum文件,因为国内无法直接访问google,这里需要将官网中的google的源改为国内源,以阿里云为例:
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=1
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOF在Master端执行:
# 安装kubeadm、kubectl、kubelet
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
# 启动kubelet服务
systemctl enable kubelet && systemctl start kubelet
# 查看版本
kubectl version --client在Node端执行:
# 安装kubeadm、kubelet
yum install -y kubeadm kubelet --disableexcludes=kubernetes
# 启动kubelet服务
systemctl enable kubelet && systemctl start kubelet初始化K8S集群
!!初始化之前一定先修改Master机的主机名,每台设备的主机名一定不能相同!!执行:
# master执行
hostnamectl --static set-hostname k8s-master # master节点
hostname $hostname # 立刻生效
# node1执行
hostnamectl --static set-hostname k8s-node1
# node2执行
hostnamectl --static set-hostname k8s-node2
# node3执行
hostnamectl --static set-hostname k8s-node3修改hosts表,执行 vim /etc/hosts 添加各个节点的映射
192.168.18.197 k8s-master
192.168.18.198 k8s-node1
192.168.18.199 k8s-node2
192.168.18.202 k8s-node3初始化Master节点
- image-repository是镜像源,由于kubeadm 默认从官网http://k8s.grc.io下载所需镜像,国内无法访问,因此需要通过image-repository指定阿里云镜像仓库地址。
- apiserver-advertise-address是Master机的IP地址,在本例中是192.168.233.10
- pod-network-cidr是POD的网段,本例中将其设为10.122.0.0/16,可自行修改。
kubeadm init --image-repository=registry.aliyuncs.com/google_containers --cri-socket=unix:///var/run/cri-dockerd.sock --apiserver-advertise-address=192.168.18.197 --pod-network-cidr=10.244.0.0/16初始化完成后提示: 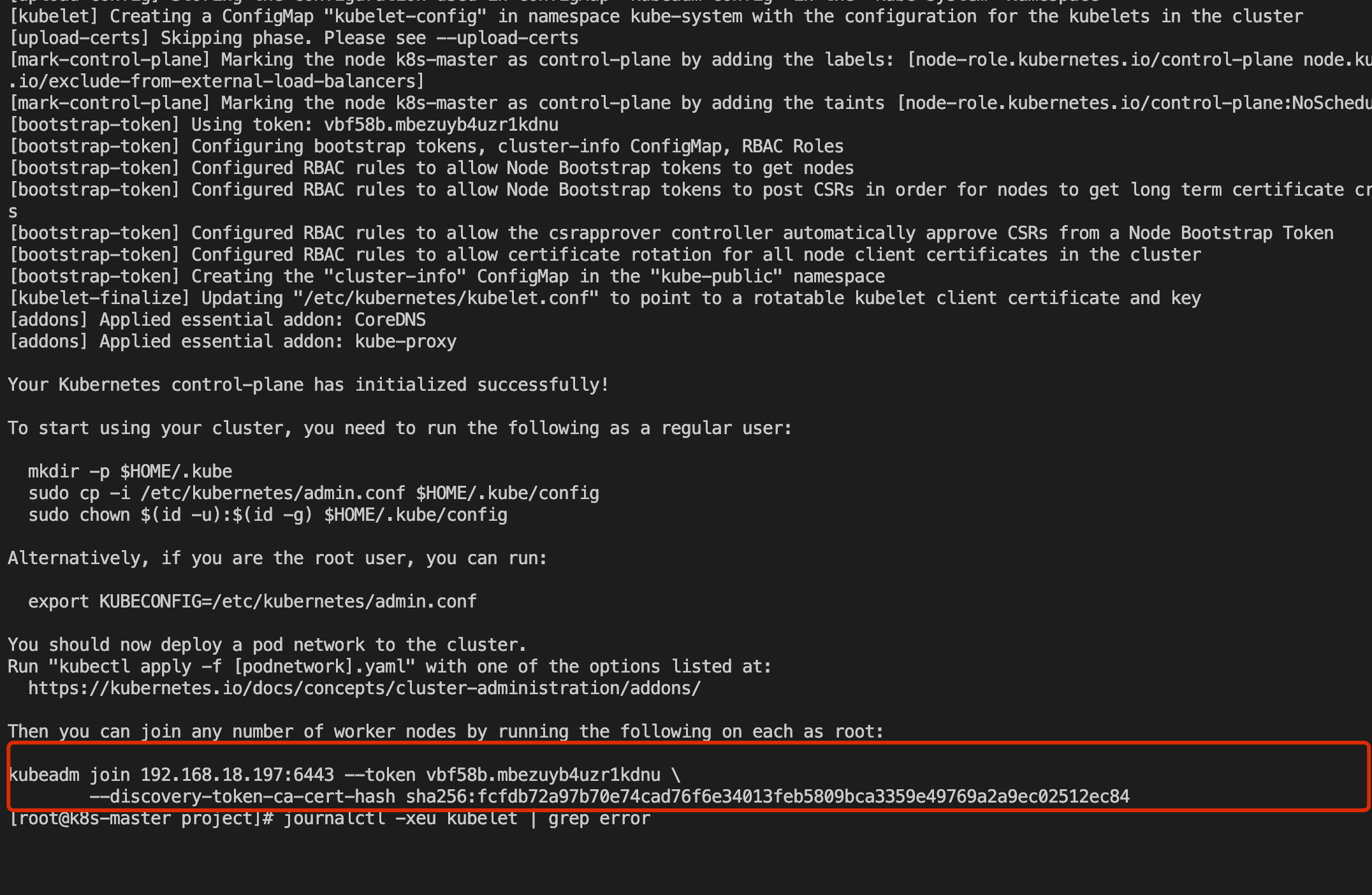
kubeadm join 192.168.18.197:6443 --token vbf58b.mbezuyb4uzr1kdnu \
--discovery-token-ca-cert-hash sha256:fcfdb72a97b70e74cad76f6e34013feb5809bca3359e49769a2a9ec02512ec84需要保存最后的token以备Node加入,现在按照上述提示,我们继续执行
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config查看Master结点的安装状态:
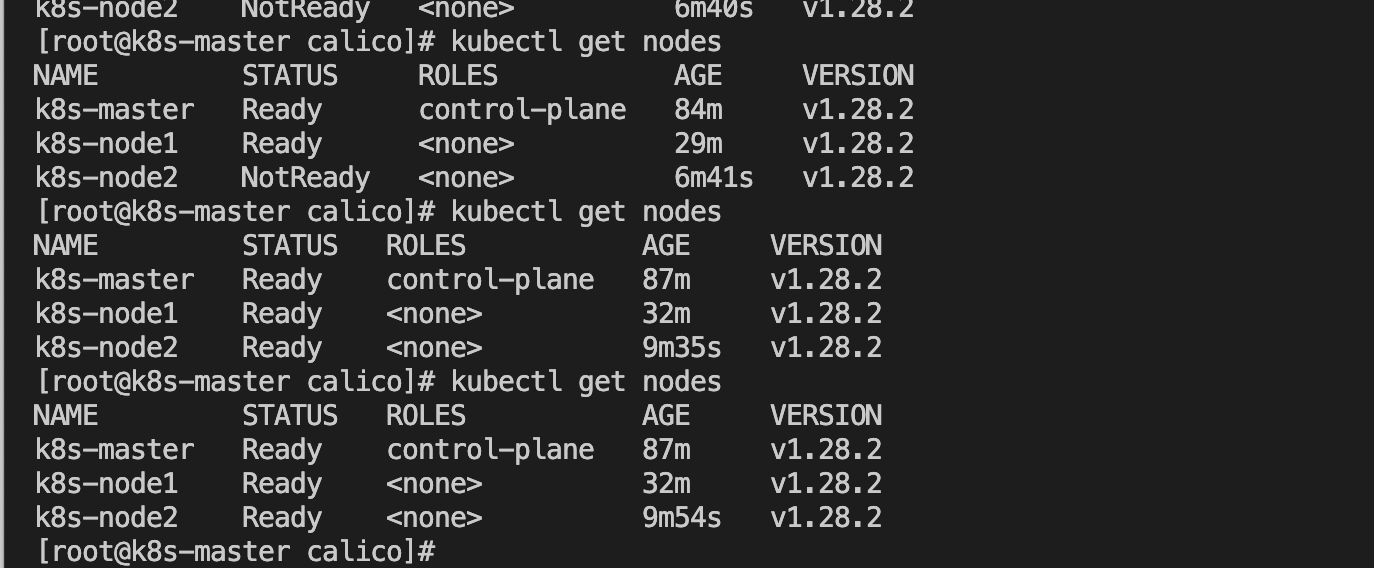
kubectl get nodes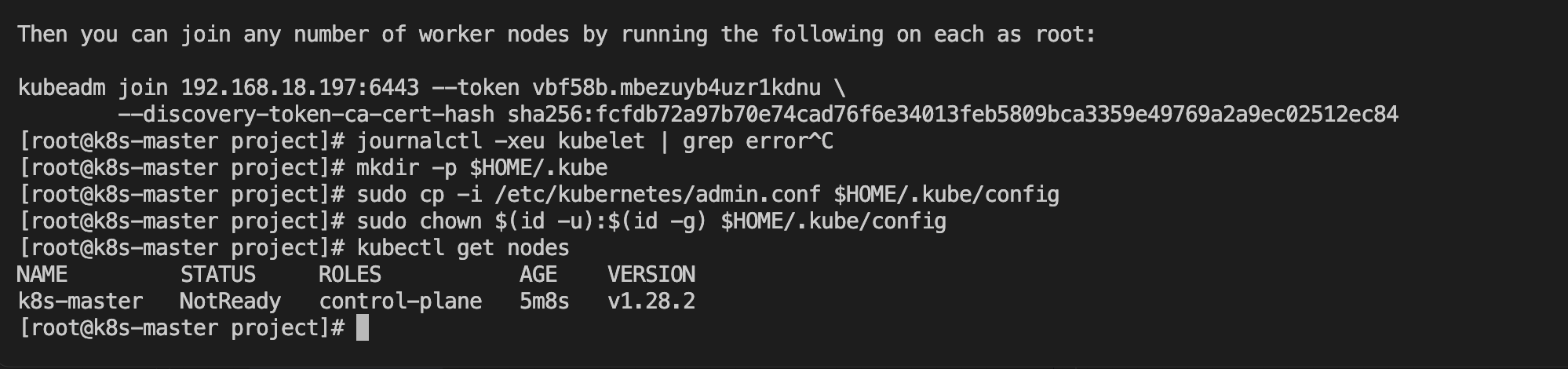
目前没有就绪,不需要管这个,在 Master设备上安装K8S路由插件Calico:
安装网络插件(Calico),master执行:
参考地址: https://docs.tigera.io/calico/latest/getting-started/kubernetes/quickstart
# 建议本地下载完后上传至服务器
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.3/manifests/tigera-operator.yaml
# 如果是下载至本地则执行:
kubectl create -f tigera-operator.yaml
wget https://raw.githubusercontent.com/projectcalico/calico/v3.27.3/manifests/custom-resources.yaml注意将custom-resiyrces.yaml的cidr配置改成初始化mater节点的ip地址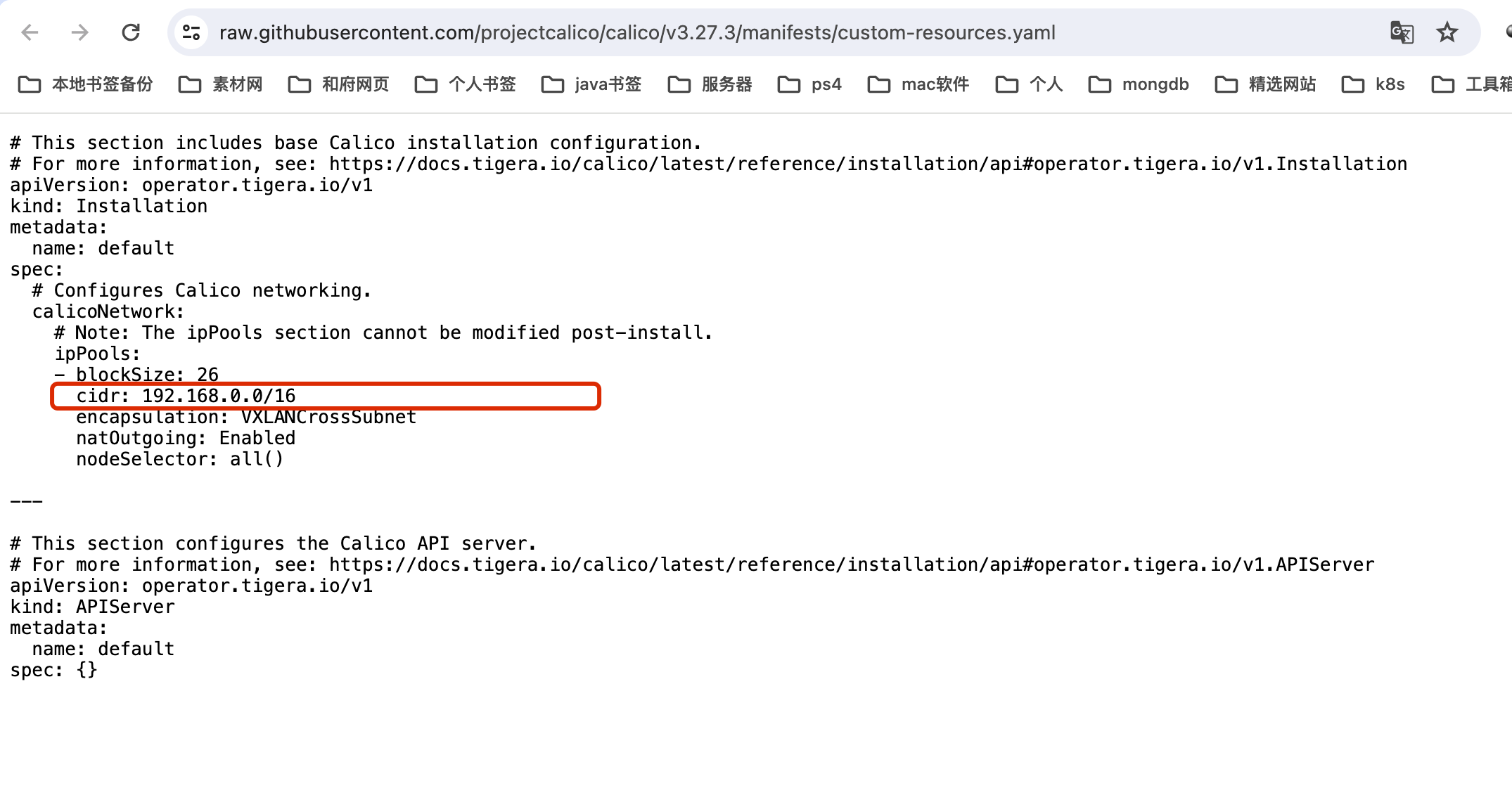
保存修改,然后执行:
kubectl create -f custom-resources.yaml- 若立刻查看master状态可能仍然不是ready状态,原因是部分pod尚未准备就绪
kubectl get nodes- 稍等片刻等待上面的pod状态变为下图,即证明网络插件Calico已经安装完毕了
watch kubectl get pods -n calico-system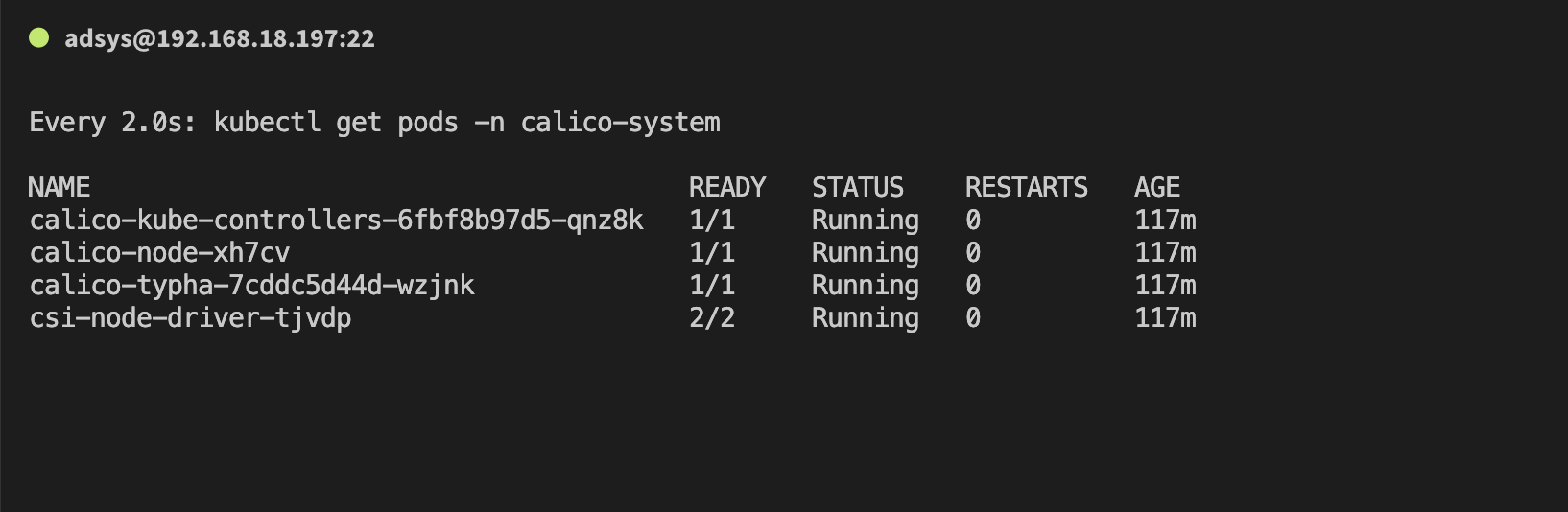
kubectl get nodes
将Node加入集群
1、在执行join指令前还需要将master节点上的/etc/kubernetes/admin.conf拷贝到node节点上.
# 格式:scp ${current_server_path}/file_name target_server_ip:${target_server_path}
$ scp /etc/kubernetes/admin.conf 192.168.18.199:/etc/kubernetes/
# 到node节点检查admin.conf文件是否传输完成
$ cd /etc/kubernetes
$ ls
admin.conf manifests
# 不要忘记将admin.conf加入环境变量,这里直接使用永久生效。
$ echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
$ source ~/.bash_profile如果第1步操作遗漏掉了的话,在执行get nodes的时候会收到以下错误:
$ kubectl get nodes
E0704 21:50:22.095009 28309 memcache.go:265] couldn't get current server API group list: Get "http://localhost:8080/api?timeout=32s": dial tcp [::1]:8080: connect: connection refused
E0704 21:50:22.099568 28309 memcache.go:265] couldn't get current server API group list: Get "http://localhost:8080/api?timeout=32s": dial tcp [::1]:8080: connect: connection refused
E0704 21:50:22.104090 28309 memcache.go:265] couldn't get current server API group list: Get "http://localhost:8080/api?timeout=32s": dial tcp [::1]:8080: connect: connection refused2、执行(kubeadm init 成功后返回的内容):
# 我这边使用的docker做的k8s集群,需要指定镜像类型,在末尾添加:
--cri-socket=unix:///var/run/cri-dockerd.sock
# 忘记了通过此命令获取: kubeadm token create --print-join-command
kubeadm join 192.168.18.197:6443 --token o3488m.mxu1izv8msmg54gc --discovery-token-ca-cert-hash sha256:fcfdb72a97b70e74cad76f6e34013feb5809bca3359e49769a2a9ec02512ec84 --cri-socket=unix:///var/run/cri-dockerd.sock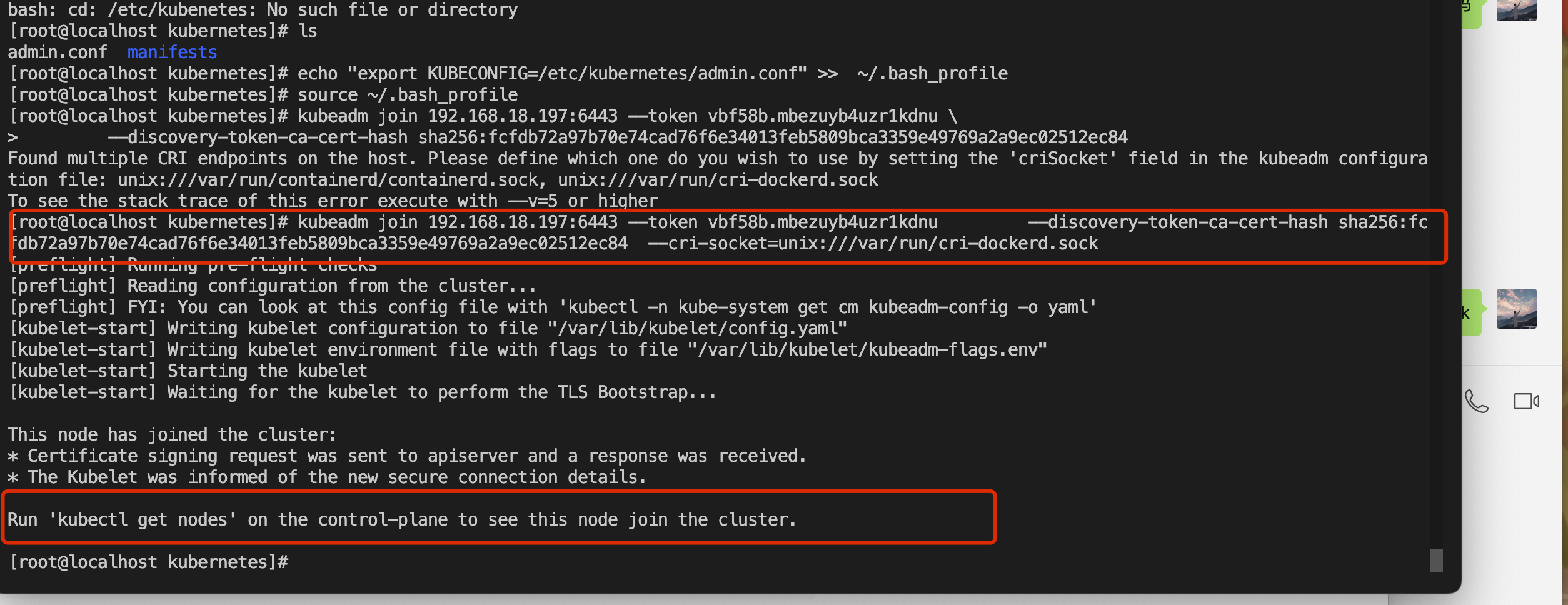
3、在任意节点执行 kubectl get nodes。如果节点都是ready的话说明整个集群状态是正常的。同时通过kubectl get pod指令查看所有pod是否正常,正常状态下,所有pod的状态都应是Running。
# node节点使用一下命令查看错误日志
$ journalctl -f -u kubelet.service$ kubectl get nodes